Rolling your own OFAC search
TL;DR
Check out the final version here! It's also available via API, here's the openapi spec. Feel free to hammer it hard - p50 search should be below ~15ms. I've clocked it at ~270 reqs/s, for a search across all OFAC & EU lists.
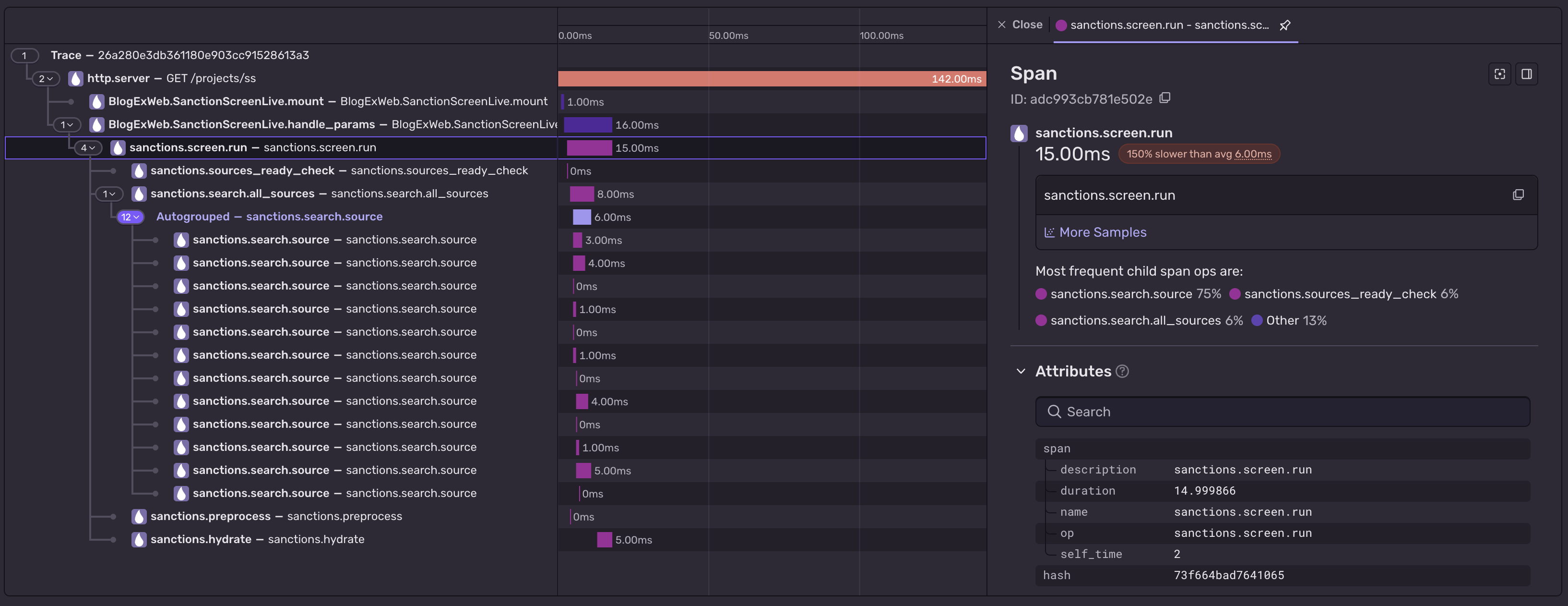
But why?
When you do anything with USD payments, one of the first things your CCO will tell you do do is that you need to screen the names in payment vs OFAC lists. Normally, your compliance team will just configure this as a rule in whatever third-party monitoring tool that you're using and be done with it, but what if you'd want to roll your own?
Scope.
Functional
The OFAC search website is a baseline that I wanted to replicate.
We take as an input a name and an entity type (indivdual / legal entity etc.), choose a confidence score from 0 to 100 (100 being an exact match, usually this is around ~80-85) and search if it occurs on any of the entries in the OFAC lists - the OFAC SDN - Specially Designed Nationals list or the OFAC non-sdn list - Consolidated List.
Non-functional
I want this to be reasonably fast, ideally under 200ms for search. - I tested a bruteforce implementation of OFAC search once in nodejs, and one search of both SDN & Consolidated lists took around 1,5 - 2s.
I want this also to be entirely within this site - which itself is written in Elixir. Now, elixir is pretty comparable to nodejs in performance, so to go faster, we'd have to go native. You can define bindings to native code in elixir using NIFs, so I decided to offload the hottest paths to Rust.
VERY non-functional
To make this as fast as we can, both the list (or rather, an index that represents the lists) and the search on that list should be kept in Rust land. We don't want to to copy or re-encode this on every call. On the other hand, we also need to access this data from Elixir. The Elixir part will be responsible for downloading and managing different lists, and it needs a stable handle to keep across requests, recover from process crashes etc.
The solution is a sandwitch - a rust-managed resource for the data and :persistent_term for the handle.
The Rust ham & cheese
Rustler - the lib for creating Rust -> Elixir NIFs, will be used to handle this.
It exposes a refcounted resource type: ResourceArc that BEAM tracks as an opaque reference. The underlying memory stays in the Rust allocator, and BEAM only sees a pointer that it can pass around.
pub struct ListIndex {
inner: Box<dyn AlgorithmIndex>,
}
#[rustler::nif(schedule = "DirtyCpu")]
fn build_ofac_index(
entries: Vec<(String, String, String, String, bool)>,
algorithm: String,
) -> Result<ResourceArc<ListIndex>, String> {
let ofac_entries: Vec<OfacIndexEntry> = entries
.into_iter()
.map(|(entry_id, name, preprocessed, display_preprocessed, is_entity)| {
OfacIndexEntry { entry_id, name, preprocessed, display_preprocessed, is_entity }
})
.collect();
let algo: Box<dyn AlgorithmIndex> = match algorithm.as_str() {
"ofac_v5_2" => Box::new(matching::ofac_v5_2::OfacV5_2::new(ofac_entries)),
// ...older versions
other => return Err(format!("unknown ofac algorithm: {other}")),
};
Ok(ResourceArc::new(ListIndex { inner: algo }))
}
fn load(env: rustler::Env, _info: rustler::Term) -> bool {
let _ = rustler::resource!(ListIndex, env);
true
}
ResourceArc::new allocates the index once, every clone of that is a chep reference count bump. OFAC searches will receive the same ResourceArc
#[rustler::nif(schedule = "DirtyCpu")]
fn search_index(
index: ResourceArc<ListIndex>,
query: String,
threshold: f64,
max_results: u64,
) -> Vec<(String, String, f64)> {
let config = SearchConfig { threshold, max_results: max_results as usize };
index.inner.search(&query, &config)
.into_iter()
.map(|m| (m.entry_id, m.matched_name, m.score))
.collect()
}
The Elixir bread
We need to store the refernce to that list somewhere, and to do that we have 2 reasonable options in Elixir - ETS or :persistent_term.
Both are shared, process-independent storage on the BEAM, but they make opposite trade-offs - ETS is great for concurrent reads and writes but every read copies the term out of the table into the caller process's heap - Elixir REALLY wants everything to be immutable. On the other heand, persistent_term reads are a pointer dereference with no copy, very optimized for reads, but writes will trigger a global GC scan. It's great for "rare writes, hot reads". It has also one very useful property - it has no owner process. That means we can spawn a Task at startup that fetches, parses and indexes the lists, then exists - and the created index will outlive it. So, :persistent_term it is.
Assembling the sandwitch
The e2e code path from boot-time list ingestion and buulding, through resource arc, with handle in :persistent_term into Rust search, looks something like this:
1. Boot: load fresh sanction lists
A supervised Task that runs at startup, it downloads lists from each configured source, parases it, and then passes it to Rust land to load the entities and build the indexes. The result handle is stored in :persistent_term and the indexes outlive the task process.
defmodule BlogEx.Sanctions.Warmer do
use Task, restart: :temporary
alias BlogEx.Sanctions.Downloader
alias BlogEx.Sanctions.Parsers.{Eu, OfacCons, OfacSdn}
alias BlogEx.SanctionScreen
@parser_modules %{ofac_sdn: OfacSdn, ofac_cons: OfacCons, eu: Eu}
def start_link(opts \\ []) do
Task.start_link(fn -> run(opts) end)
end
def run(opts) do
config = Application.get_env(:blog_ex, :sanction_screen, [])
sources = Keyword.get(config, :sources, [])
algorithms = Keyword.get(opts, :algorithms, @default_algorithms)
sources
|> Task.async_stream(
fn {slug, src} -> warm_source(slug, src, algorithms) end,
max_concurrency: 3,
timeout: :timer.minutes(5)
)
|> Stream.run()
end
defp warm_source(slug, src, algorithms) do
parser = Map.fetch!(@parser_modules, slug)
with {:ok, raw} <- Downloader.fetch(parser),
{:ok, parse_result} <- parser.parse(raw),
{:ok, version_key} <-
SanctionScreen.ingest_parsed(parse_result, algorithms: algorithms) do
Phoenix.PubSub.broadcast(
BlogEx.PubSub,
"sanctions:sources",
{:sanction_source_ready, slug, version_key}
)
end
end
end
2. Ingestion - build indexes
For efficient search, we allow each algorithm version to build it's own index, this involves a common preprocessing step. All indices are also partioned by entity_type (individual, entity, vessel, aircraft) by default.
defp build_indexes(parse_result, version_key, algorithms, opts, index_manager) do
name_entries = extract_name_entries(parse_result.entries)
preprocessed_entries =
Enum.map(name_entries, fn {entry_id, name, entity_type} ->
preprocessed = Preprocessing.preprocess(name, entity_type)
%{entry_id: entry_id, name: name, preprocessed: preprocessed, entity_type: entity_type}
end)
config = %{
threshold: Keyword.get(opts, :threshold, @default_threshold),
max_results: Keyword.get(opts, :max_results, @default_max_results)
}
partitions = Enum.group_by(preprocessed_entries, & &1.entity_type)
for algo <- algorithms,
{entity_type, entries} <- partitions,
entries != [] do
mod = Algorithm.module_for(algo)
state = mod.build(entries, config)
IndexManager.store(
parse_result.source_slug,
version_key,
algo,
entity_type,
state,
index_manager
)
end
end
3. The IndexManager
A thin wrapper over :persistent_term. The "state" stashed per key is exactly the ResourceArc return by Rust.
defmodule BlogEx.Sanctions.IndexManager do
def store(source_slug, version_key, algorithm, entity_type, state, namespace \\ __MODULE__) do
key = {source_slug, version_key, algorithm, entity_type}
:persistent_term.put(index_key(namespace, key), state)
registry = :persistent_term.get(registry_key(namespace), %{})
:persistent_term.put(registry_key(namespace), Map.put(registry, key, true))
:ok
end
def get(source_slug, version_key, algorithm, entity_type, namespace \\ __MODULE__) do
case :persistent_term.get(
index_key(namespace, {source_slug, version_key, algorithm, entity_type}),
:not_found
) do
:not_found -> {:error, :not_found}
state -> {:ok, state}
end
end
defp registry_key(namespace), do: {__MODULE__, namespace, :registry}
defp index_key(namespace, key), do: {__MODULE__, namespace, :index, key}
end
4. The search
SanctionScreen.search/2 preprocesses the query once per requested entity
type, then runs one task per (version, entity_type) triple. Each task
pulls its index out of :persistent_term and dispatches to the algorithm
module.
def search(name, opts \\ []) do
algorithm = Keyword.get(opts, :algorithm, :jaro_winkler_native)
entity_type = Keyword.get(opts, :entity_type, :all)
list_manager = Keyword.get(opts, :list_manager, ListManager)
index_manager = Keyword.get(opts, :index_manager, IndexManager)
target_types =
case entity_type do
:all -> @entity_types
et when et in @entity_types -> [et]
end
preprocessed_by_type =
Map.new(target_types, fn et -> {et, Preprocessing.preprocess(name, et)} end)
mod = Algorithm.module_for(algorithm)
config = %{threshold: ..., max_results: ...}
versions = list_manager |> ListManager.list() |> filter_versions(opts[:sources])
tasks =
for {version_key, meta} <- versions,
et <- target_types,
do: {version_key, meta, et}
raw_matches =
tasks
|> Task.async_stream(
fn {version_key, meta, et} ->
case IndexManager.get(meta.source_slug, version_key, algorithm, et, index_manager) do
{:ok, state} ->
results = mod.search(state, preprocessed_by_type[et], config)
Enum.map(results, &Map.merge(&1, %{version_key: version_key}))
{:error, :not_found} ->
[]
end
end,
ordered: false,
timeout: 15_000
)
|> Enum.flat_map(fn {:ok, list} -> list end)
# ...rank, take max_results, hydrate to full ScreeningResult...
end
Now back to functional - How does OFAC search even work?
The FAQ provides some details:
Sanctions List Search will first look for potential matches based on the first letter of input search terms and by checking for matches at least 50% or more similar based on edit distance. (...)
Sanctions List Search then uses two matching logic algorithms, and two matching logic techniques to calculate the score. (...)
The first technique involves using the Jaro-Winkler algorithm to compare the entire name string entered against full name strings of potential match entries on OFAC's sanctions lists.
The second technique involves splitting the name string entered into multiple name parts (for example, John Doe would be split into two name parts). Each name part is then compared to name parts on all of OFAC's sanctions lists using the Jaro-Winkler and Soundex algorithms. The search calculates a score for each name part entered, and a composite score for all name parts entered.
Sanctions List Search uses both techniques each time the search is run and returns the higher of the two scores in the Score column.
Ok so we have a combination of fuzzy an phonetic matching. It mentions both the Jaro-Winkler and Soundex algorithms.
Unfortunately diving deeper in the FAQs reveals that there was an additional algorithm change in 2021 that introduced "new algorithm to the tool's fuzzy logic search funcitonality', and the exact details are unknown.
On the other hand, it's rare you'll come across a ticket that will provide as much details as the OFAC FAQ did, so I can't complain.
Preprocessing
We need to normalize both the list and the input before comparison, and as it's an user input and even worse, potentially multi-lingual user input, we have a lot of stuff to cleanup.
Let's say we need to screen the extreme case - the estimeed "Dr. José García III" in his full glory, we need to cleanup both the ofac entries and the search itself. To do that, I used the following pipline:
lowercase-> "dr. josé garcía iii"unicode normalization- unicode lets you represent the same character in multiple ways, for example é can be one codepoint or two (e + accent mark), so I applied the NFKD normalization that expands everyting into simplest pieces, so the 2 strings that look identical can actually match in code, regerdless of how they were encoded. So "dr. josé garcía iii" get's his é decomposed into é → e + ◌́diacritics- strip the accents marks and replace all these ą and ę, leaving dr. Garcia as "dr. jose garcia iii"transliteration- tries to convert non-latin scripts into ASCII equivalent, using the any_ascii crate. Dr. Garcie is not affected by this but we're prepared for Владимир → Vladimirpunctuation removal- "dr jose garcia iii",title removal- leaving "jose garcia iii", no longer a dr.suffix removal- "jose garcia" and no longer the 3rdwhitespace cleanup- no-op here, but any stray spaces will be cleaned up, and duplicate merged into one
So we reduced estimeed "Dr. José García III" to less estimeed "jose garcia" but we'll make up the lack of titles with ease of comparison.
Note
Not sure what if any preprocessing is used in the OFAC search website, but for sure it doesn't support transliteration, so if you search for Владимiр Путин you'll get no matches. In that regard, this is an improvement over the OFAC search, but realistically, USD wires or ACHs will be bounced if they contain non-ascii characters, so they probably just did not bother. For the purposes of eu-maxxing we'll keep that in.
Prefiltering
As of May 2026, the OFAC SDN list has 18,959 entires. Many entries also have multiple aliases associated with them, and each such alias needs to be checked - EU lists have even more aliases, I've seen 20+ aliases for some organizations like Calea Luminoasă, one for each official EU language.
This adds up very quickly, especially if we add more lists, and if we have to run our matching algorithm on every name, we won't get to the desired below 200ms. The solution to that is to aggresively filter out entries that have no chance of matching anything.
The FAQ mentioned that OFAC is using a combination of first-letter-match and 50% edit distance, which seems also slow to me (to calculate edit distance, you need to still compare the query to the name on the list, and the query is not known beforehand so we cannot pre-compute anything).
We can do better then that - to do that, let's do the same as the pg_trgm module uses for fuzzy matching - trigrams.
Trigram Index, Inverted
Trigram is a "group of three consecutive characters taken from a string", so if we take "Putin" we get put, uti, tin. We can assume that if there are no matching trigrams between the name on the list and the query, then it's unlikely that running our matching algorithm on that will produce any matches. To find candidates with common trigram we can build a simple hash map [trigram] -> [entries containing that trigram]. This is a lookup that maps terms to location where they appear, so we can call it an 'Inverted Index' (still just a hashmap tho).
Here's how the search on the 'Inverted Trigram Index' looks like:
-
[ahe]
→
06 maher assad
-
[ale]
→
01 alexander lukashenko
-
[and]
→
01 alexander lukashenko
-
[ash]
→
01 alexander lukashenko 02 viktor lukashenko 05 bashar assad
-
[ass]
→
05 bashar assad 06 maher assad
-
[bas]
→
05 bashar assad
-
[der]
→
01 alexander lukashenko
-
[enk]
→
01 alexander lukashenko 02 viktor lukashenko
-
[exa]
→
01 alexander lukashenko
-
[har]
→
05 bashar assad
-
[hen]
→
01 alexander lukashenko 02 viktor lukashenko
-
[her]
→
06 maher assad
-
[ikt]
→
02 viktor lukashenko
-
[jon]
→
03 kim jong un 04 kim jong il
-
[kas]
→
01 alexander lukashenko 02 viktor lukashenko
-
[kim]
→
03 kim jong un 04 kim jong il
-
[kto]
→
02 viktor lukashenko
-
[lex]
→
01 alexander lukashenko
-
[luk]
→
01 alexander lukashenko 02 viktor lukashenko
-
[mah]
→
06 maher assad
-
[nde]
→
01 alexander lukashenko
-
[nko]
→
01 alexander lukashenko 02 viktor lukashenko
-
[ong]
→
03 kim jong un 04 kim jong il
-
[sad]
→
05 bashar assad 06 maher assad
-
[sha]
→
05 bashar assad
-
[she]
→
01 alexander lukashenko 02 viktor lukashenko
-
[ssa]
→
05 bashar assad 06 maher assad
-
[tor]
→
02 viktor lukashenko
-
[uka]
→
01 alexander lukashenko 02 viktor lukashenko
-
[vik]
→
02 viktor lukashenko
-
[xan]
→
01 alexander lukashenko
This gives as O(1) lookup for candidates and massivly reduces the number of candidates we need to check.
Note
I've actually tried the first letter + 50% edit distance combo that OFAC mentioned in the FAQ, it worked fine but it was much slower then trigram, and it didn't have any effect on the score benchmarks.
Now that we don't need to do as much, we can focus on doing the little that's left well, let's start fuzzy matching.
V1 - simple Jaro - Winkler
First fuzzy algorithm mentioned by - Jaro-Winkler compares 2 strings and gives us a score between 0 and 1 on how similar are those 2 strings - 0 being completely different and 1 identical.
The base of that is the Jaro score - it looks at three things:
- How many characters match
- How many characters are out of order
- The lenghts of both strings
The Winkler part of the JW is a later modification that adds a "prefix bonus" - strings that share the same starting characters get a score boost. This makes the algorithm "front-biased" - test vs xest
scores lower than test vs tesx, even though both have just one character different.
Elixir has it's own jaro-similarity function, but for now we'll go native and use jaro-winkler from the strsim create. So we first take the list, run pre-processing on it, and then run JW comparison, and return any matches greater then score. Here's a demo of that
DEMO: OFAC v1 — Plain Jaro-Winkler ▶ EXPAND
Pretty good! You can find Vladimir Putin pretty easily! It will also find Vladim Ptin. Thanks to all our pre-processing steps it also catches all the cyrylics - "Владимир Путин" and "Владимiр Путин", and thanks to pre-filtering, it's blazingly fast™, with consistent under ~6ms queries.
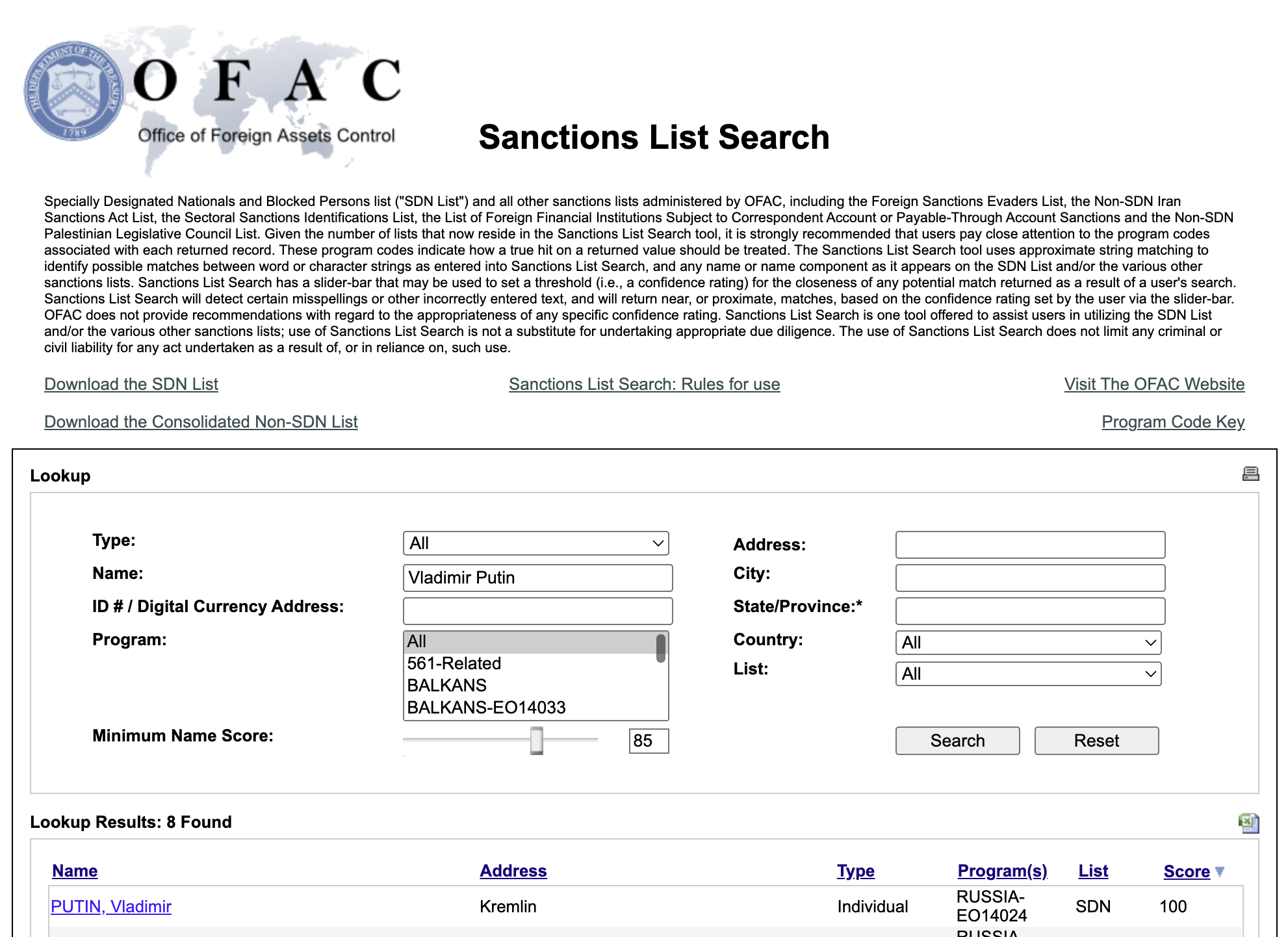
How about "Putin Vladimir"? Well, in this case we get a big fat 0. The OFAC search website handles it just fine:
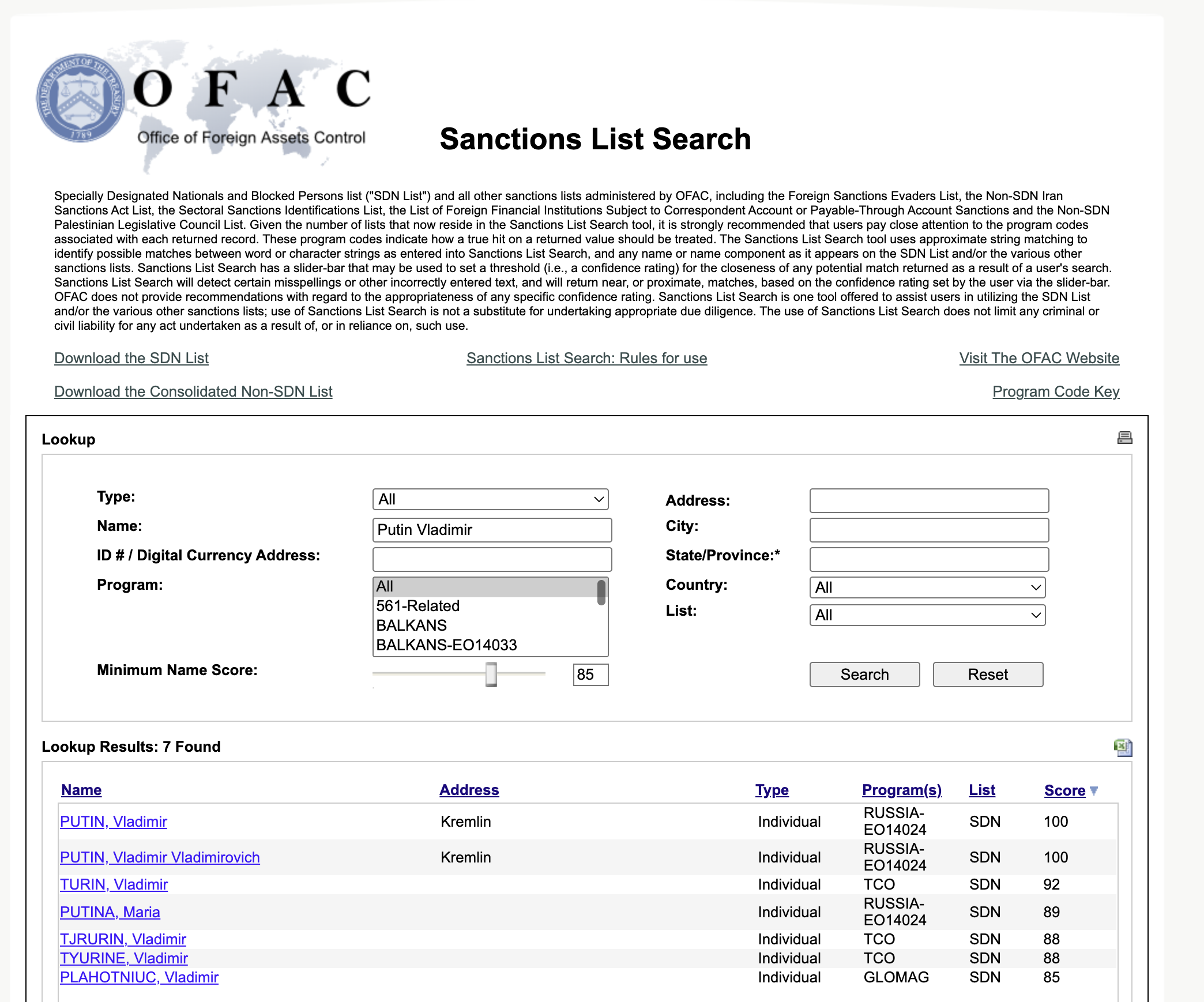
Even "Putin" itself causes two 100 points matches:
As stated in the FAQ, OFAC website does something with name parts as well, not full names only, let's try to replicate that.
V2 - Token Jaro-Winkler
OFAC search tries to compare each token in the name separatly, and then produces a "composite score" out of them. To replicate that, we can tokenize both sides of the target / query, and for each query token find the best JW match among the target tokens.
This should fix bot the name-parts reordering - tokens matched individually, regardless of order (Putin Vladimir instead of Vladimir Putin) and partial queries ("putin" matches "putin" token in "vladimir putin" directly.
Now all that's left is the 'composite score', we'll do the simplest thing here, final score will be the max(full_string_jw, average_of_best_token_matches) so the full-string path from v1 is still there as a fallback. As naive as it gets. Here's the demo:
DEMO: OFAC v2 — Token Jaro-Winkler ▶ EXPAND
Works great! Reordering works as well. However, it's super sensitive and ends up catching a lot of stuff it shouldn't. Try putyn - one letter off. You get the 5 Putins/Putinas you'd want, and then a pile of unrelated matches.
They get in because we're averaging the best per-token JW, and any single token token that's close enough to putyn will cause entire thing to match.
The issue is, PUT against putyn scores JW = 0.907. That's the same score as PUTIN against putyn. JW gives a big bonus for a shared prefix, so a 3-letter token starting with the same letters looks identical to the actual surname. PTY is 0.880, PUTILIN is 0.853. Threshold is 0.85, so they all sneak through.
It's even worse on real names. mishustyn returns 19 in v2 - 8 actual Mishustins, the rest are unrelated (Mishan al-Juburi, in a few transliterations, two unrelated Mishins and a Mishkin). bastrykin is the correct spelling, not even a typo, and v2 still returns 25: 1 actual Bastrykin and 24 false positives, from BASTION EK to Lebanese al-BASRI, BALESTRINI, BOYARKIN.
DEMO: OFAC v2 — Token Jaro-Winkler ▶ EXPAND
False positives are always very annoing for the compliance teams, as every potential match has to be explicitly resolved and documented, so how do we fix this? Well, FAQ said something about SoundEx.
V3 - Adding SoundEx
SoundEx is a phonetic encoding, that encodes a word down to a code, based on how it sounds. The algorithms keeps the first letter as-is, drops all vowels and specific letters, and then maps the remaining consontants into six groups, based on where the sound is produced in the mouth, so cases like Robert" and "Rupert" yield the same "R163" encoding.
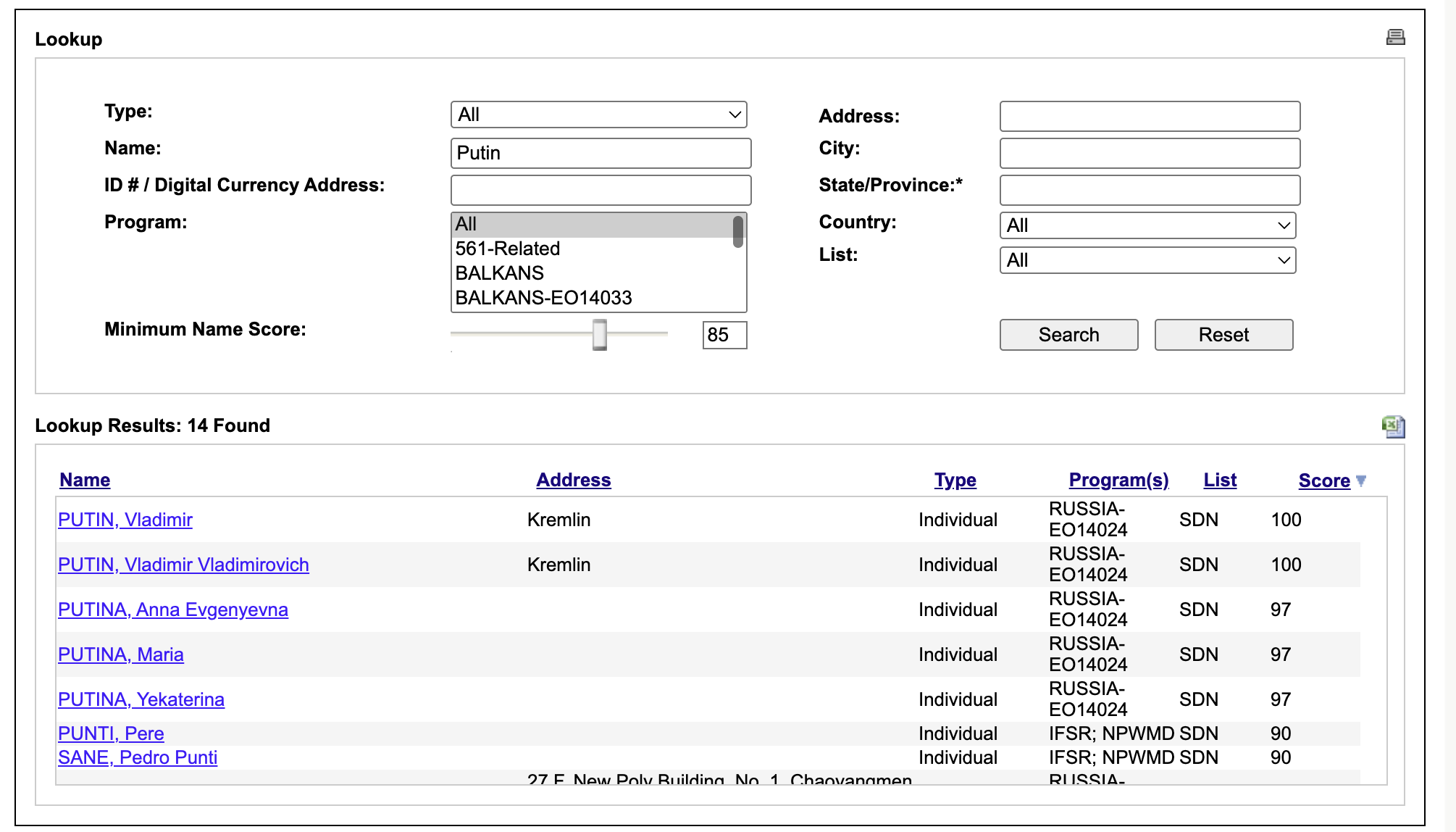
How does OFAC uses that? We can get an idea by searching both "Robert" and "Rupert".
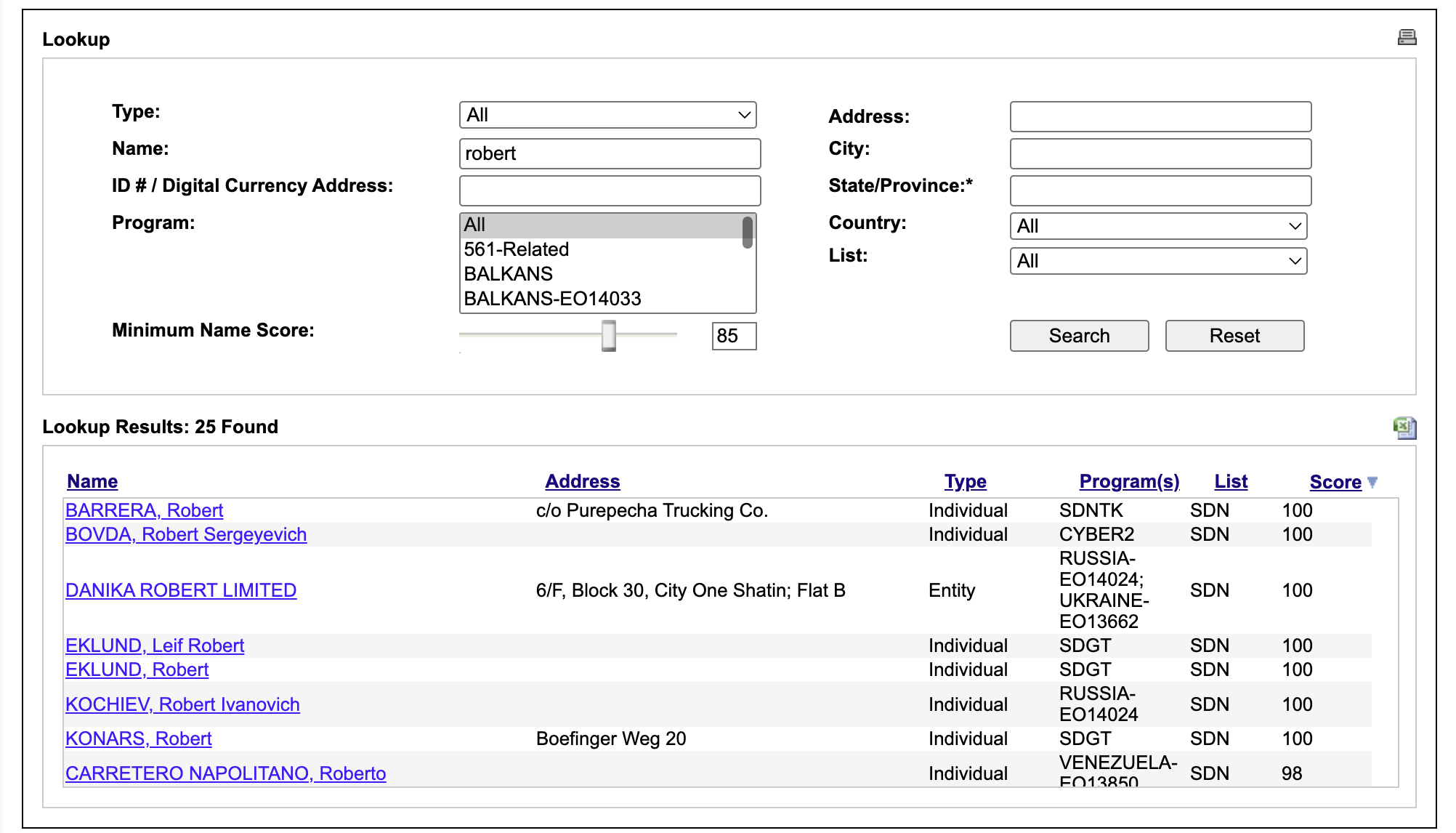
Robert produces 25 matches, 7 of that with a score of 100. So the token-matching algortihm kicks in and if a name part matches Robert it will match exactly. How about if we search for a token that has the same SoundEx encoding - Rupert?
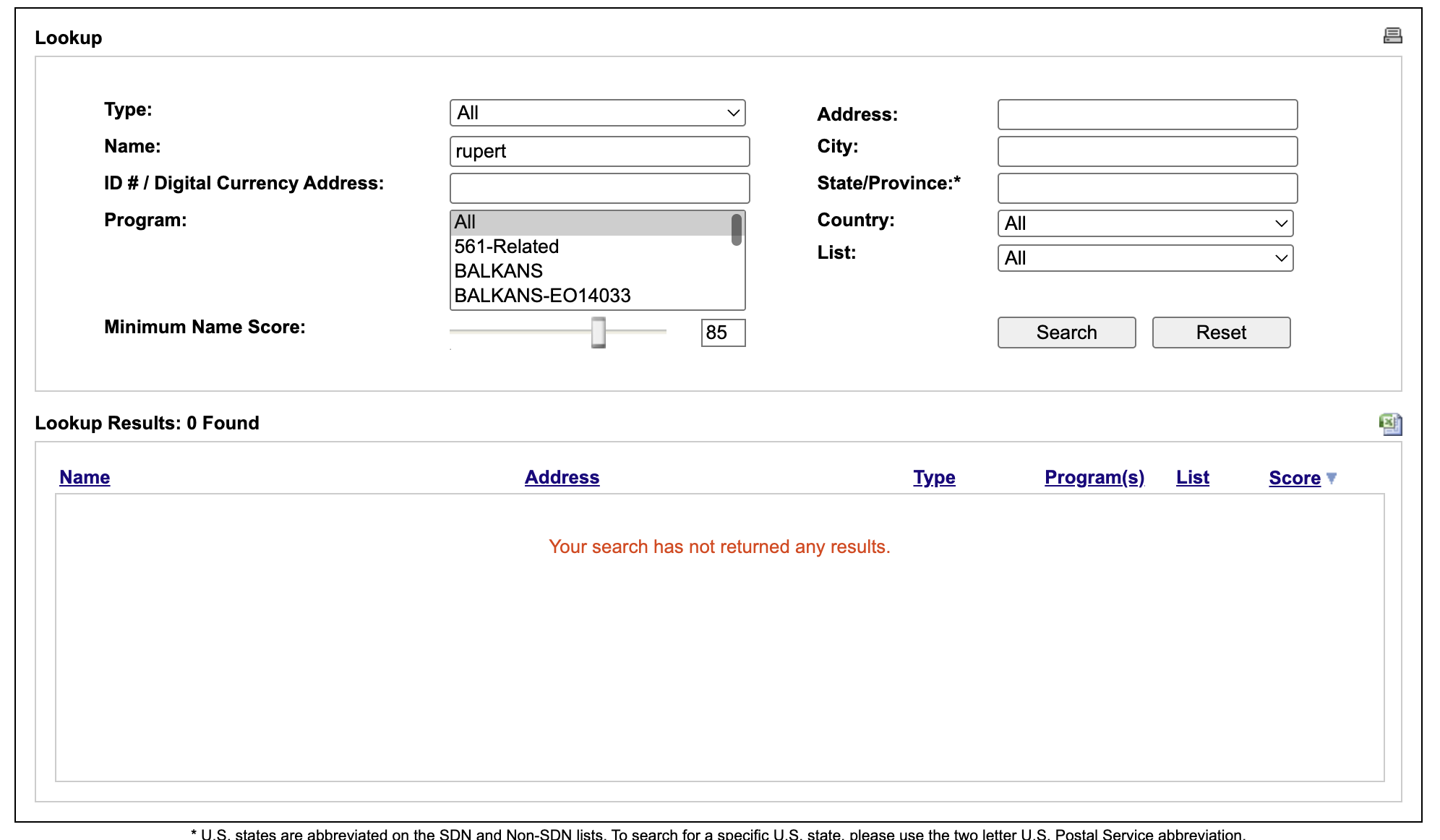
Hm, no matches at all. This would suggest that OFAC is doing something else with SoundEx, maybe it doesn't use it for matching, but rather for rejecting potential false positives? Let's try that approach - a token pair must celar the JW threshold and share a Soundex code. And since Soundex ignores length - it truncates after first three encoded consonants, so 'vladimir' and 'vladimirovich' both encode to V435, let's also add a token/lenght ratio check that will reject token pairs with mismatched lengths.
So for any (query_token, record_token) pair the condition now is:
- pass if JW >= 0.95
- OR (JW >= threshold AND length_ratio >= 0.65 AND soundex(qt) == soundex(rt)
Let's run putyn again:
DEMO: OFAC v3 — Token Jaro-Winkler + Soundex ▶ EXPAND
5 matches, exactly the Putins/Putinas. Let's check the cases that V2 matched:
PUTIN- JW 0.907, SoundExP350, ratio 5/5 = 1.00. Passes via the secondary path.PUTINA- JW 0.876, SoundExP350, ratio 5/6 = 0.83. Passes.PUT- JW 0.907, SoundExP300(different), ratio 3/5 = 0.60 (under 0.65). Rejected.PTY- JW 0.880, SoundExP300(different), ratio 0.60. Rejected.PUTILIN- JW 0.853, SoundExP345(different), ratio 5/7 = 0.71. Rejected.
PUT is the easy one - soundex differs and length ratio is under 0.65, either alone would've killed it. PUTILIN is where v3 kicks in - same first letter, similar length, JW was already on the threshold anyway - but the soundex (P345 vs P350) catches it. That extra L between T and N flips the third digit. SoundEx is bucketing by how the consonants sound, and a stray consonant in the middle is enough to say "no, different name."
Same story for the other queries:
mishustynvsmishan-M223vsM250bastrykinvsbastion-B236vsB235bastrykinvsboyarkin-B236vsB625
None of them clear, and v3 drops them.
v3 cleans up the single-token typos nicely. But click Vladimir Putin in the v3 demo above and you'll get 49 matches. That's worse than v2 was on putyn. And the query isn't even a typo - it's exactly the name we're looking for. What can we do about it?
V4 - Per-token gating
Most of the 49 are unrelated Vladimirs on the lists - TURIN, TYURIN, KIRIYENKO, USTINOV, etc. There are a couple of vessels and entities there as well.
What broke? The score in v3 is still max(full_string_jw, token_avg). The token average for "vladimir putin" vs "vladimir kiriyenko" is (1.0 + jw(putin, kiriyenko)) / 2 ≈ 0.75, well below threshold - that part actually works. The problem is the full-string JW between "vladimir putin" and "vladimir kiriyenko" lands around 0.88. They share "vladimir " as a 9-character prefix, JW maxes out the prefix bonus after 4 chars anyway, and the rest is close enough to clear 0.85. The full-string path doesn't care that the surname is a total mismatch, and max(...) only needs one path to fire.
So for multi-token queries we'll drop the full-string path entirely. Score is purely token-based. And we'll add a per-token gate - each query token has to find at least one record token with JW above threshold, otherwise the record scores 0. Single-token queries keep the v3 logic with the soundex secondary, that part already works.
DEMO: OFAC v4.0 — Adaptive Gating ▶ EXPAND
Vladimir Putin: 2 matches, the actual Putins - exactly the same as the OFAC search. Sergei Lavrov: 3. Mikhail Mishustin: 4.
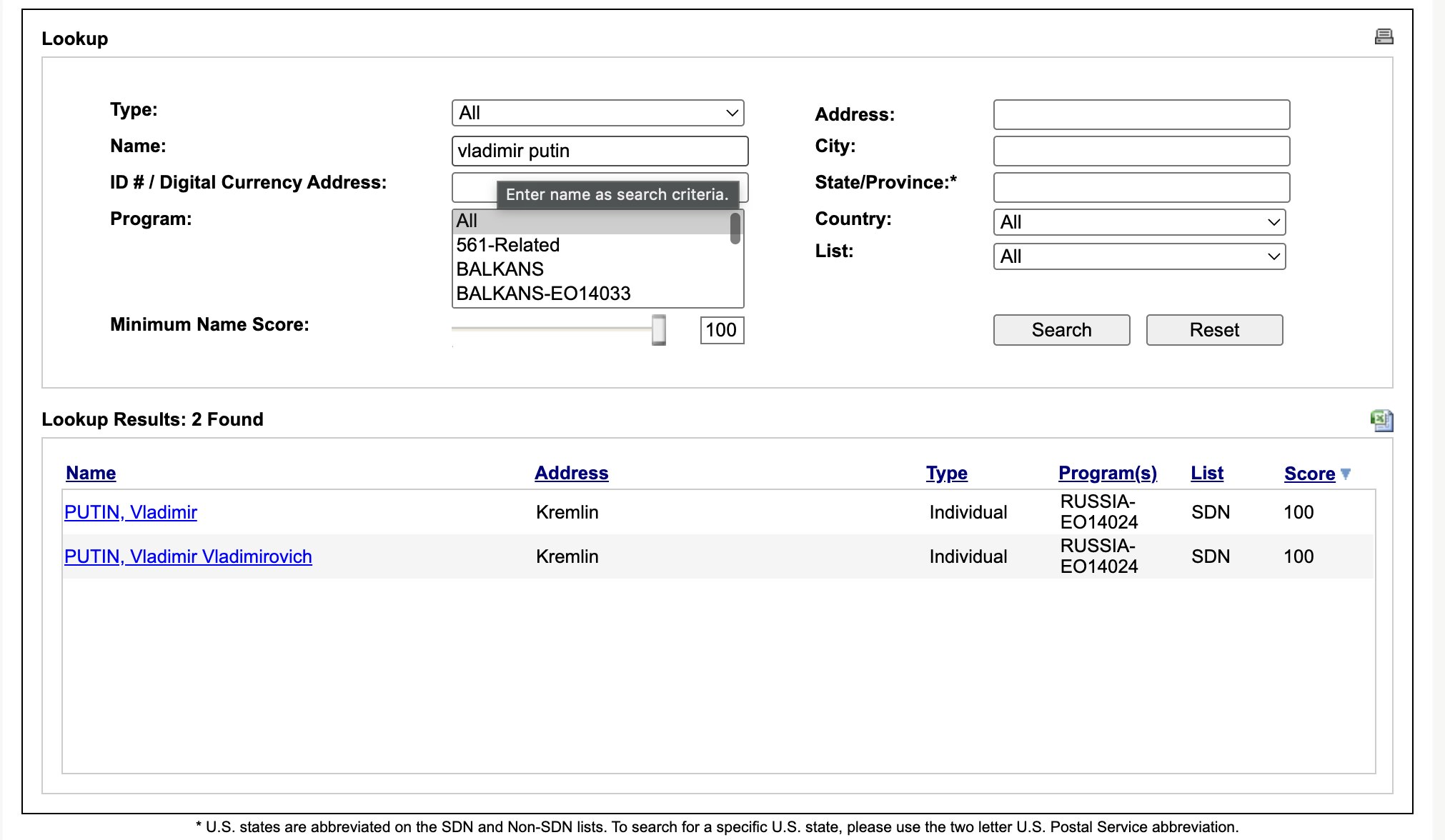
Dropping short tokens
Try al qaeda in the v3 demo -200+ matches.
DEMO: OFAC v3 — Token Jaro-Winkler + Soundex ▶ EXPAND
The actual AL QAEDA entries are at the top at 1.0, then the rest is records whose surname happens to start with AL-. The mechanism is the same as before but inverted: the 2-char al query token finds a perfect 1.0 match against AL in basically every record with that prefix, qaeda finds some moderate JW with the surname, average clears 0.85.
The 2-char al carries no information, it's an article. Same with el, de, un, bin. They appear everywhere and discriminate nothing. When you search for it in the ofac website, it says that it returns too many matches:
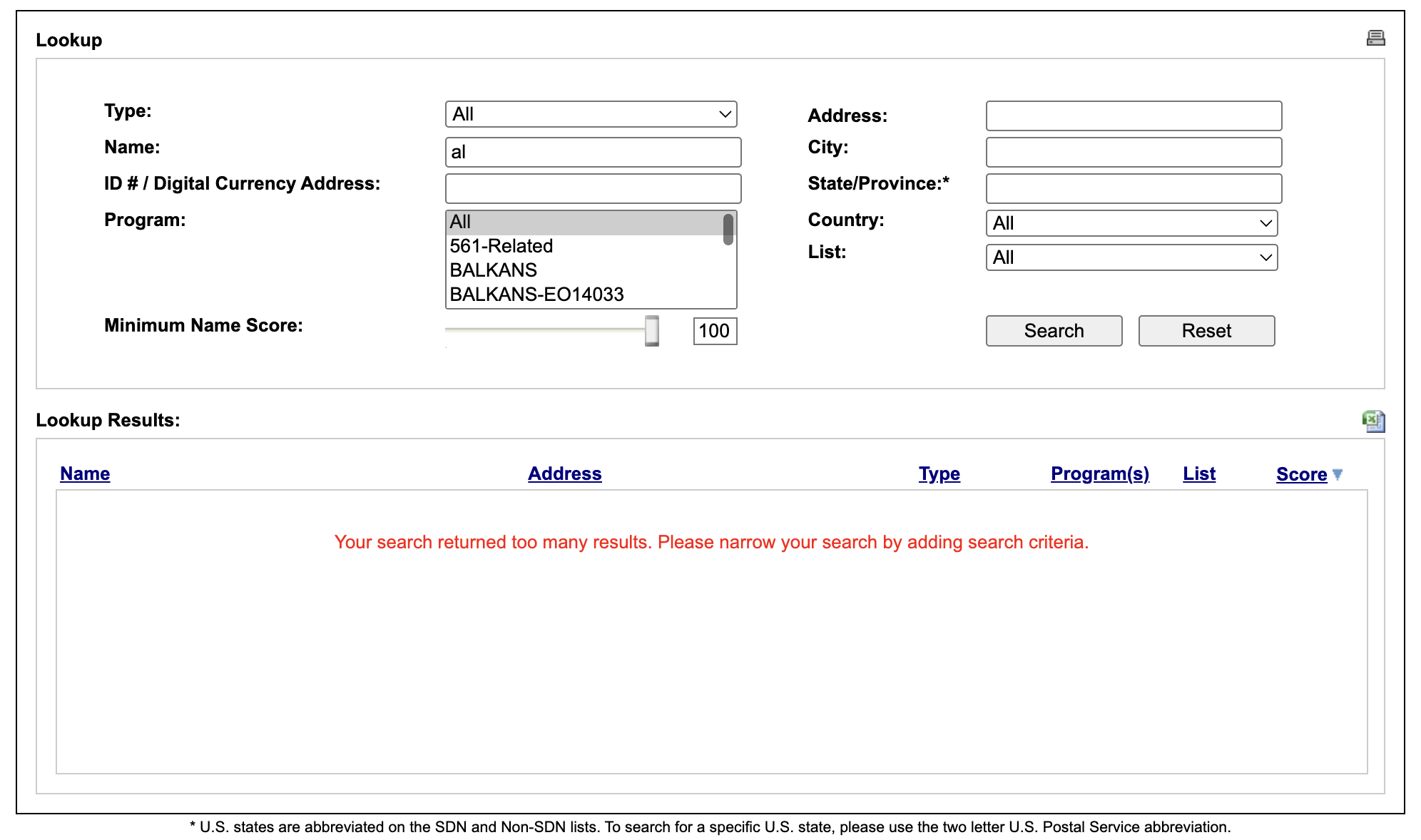
So in v4 we drop query tokens shorter than 3 characters from scoring entirely.
DEMO: OFAC v4.0 — Adaptive Gating ▶ EXPAND
In v4, al qaeda drops to 31 matches. Kim Jong Un benefits too - the 2-char un gets dropped, effective query is [kim, jong], and the gate works on the meaningful tokens.
v5 - STRAWGRASPING
v4 works well and catches the big failure modes, and the search results are very defensible. So at this point, the wins are pretty small, but anyways, here are some of the ideas I explored and bundled together, so it can justify the major version bump (not really).
v5.0 - JW score correction
Our scores come out lower than OFAC's. So, I've collected 26 (our_jw, OFAC_score) pairs from OFAC's tool, picked a simple correction shape - push each of our scores a fraction of the way toward 1.0 - and tried different fractions until the adjusted scores lined up with OFAC's as closely as possible. 0.08 won, so: adjusted = jw + 0.08 * (1 - jw).
DEMO: OFAC v5.0 — Residual Correction ▶ EXPAND
v.5.1 - greedy token pairing.
v4 lets each query token pick its single best record-token match, which means two query tokens can both grab the same record token and we end up counting it twice. Try Sergei Sergeyev in the v4 demo above - Sergei IVANOV clears threshold at 0.96 because both sergei and sergeyev pair against the record's Sergei, even though there's no Sergeyev anywhere in IVANOV's name.
The fix is to score every (query_token, record_token) pair, sort them descending, take the top pair, mark both tokens used, repeat - each token contributes at most once.
Another edge case to cover is the prefix-pair rejection: if one token is a strict prefix of the other and at least 4 chars long, throw the pair out, so iran doesn't match iranian anymore.